LoRA
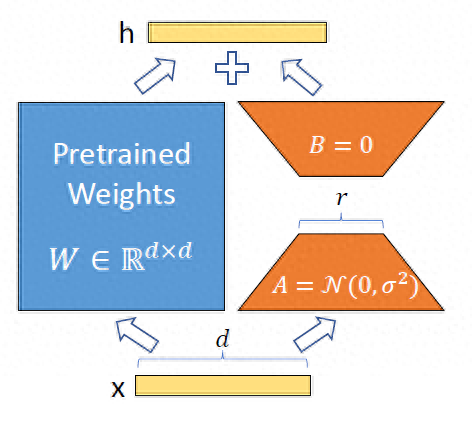
在学习完“神经网络与矩阵”的时候,读者都可以知道神经网络都可以用矩阵来表示。LoRA 假设微调期间的权重更新可以很好地近似于低秩矩阵。LoRA不会更新全权重矩阵W,而是将更新分解为两个较小的矩阵A和B。
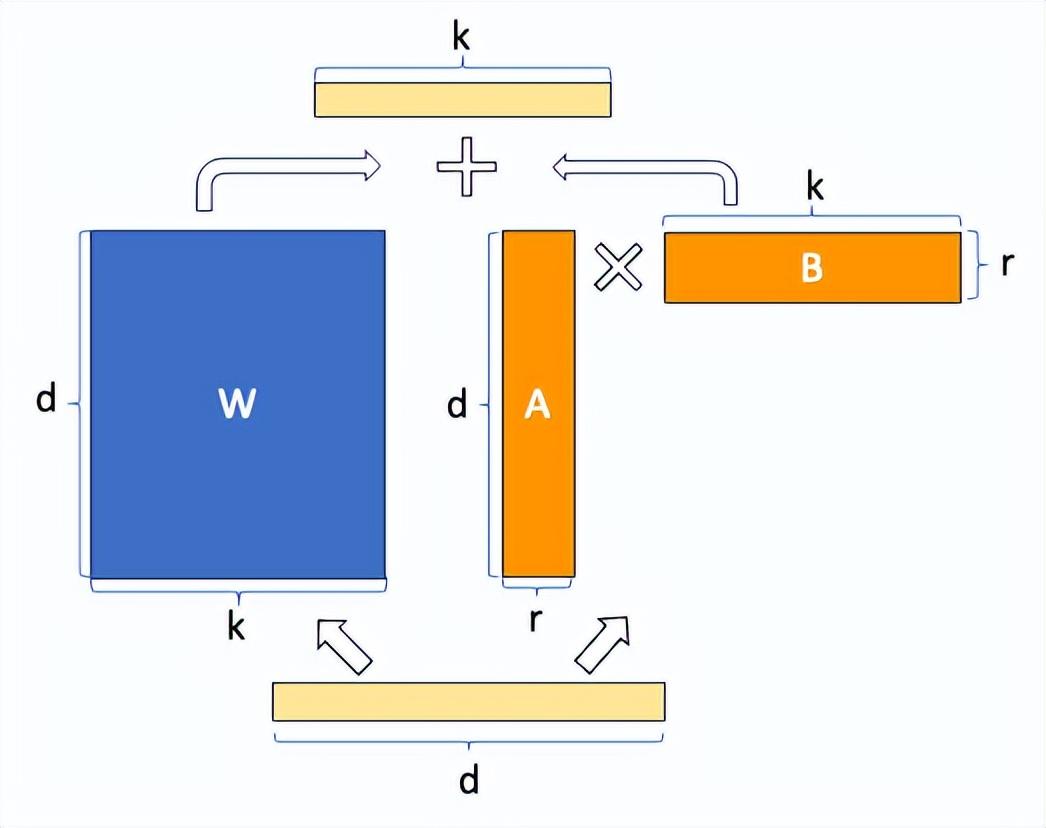
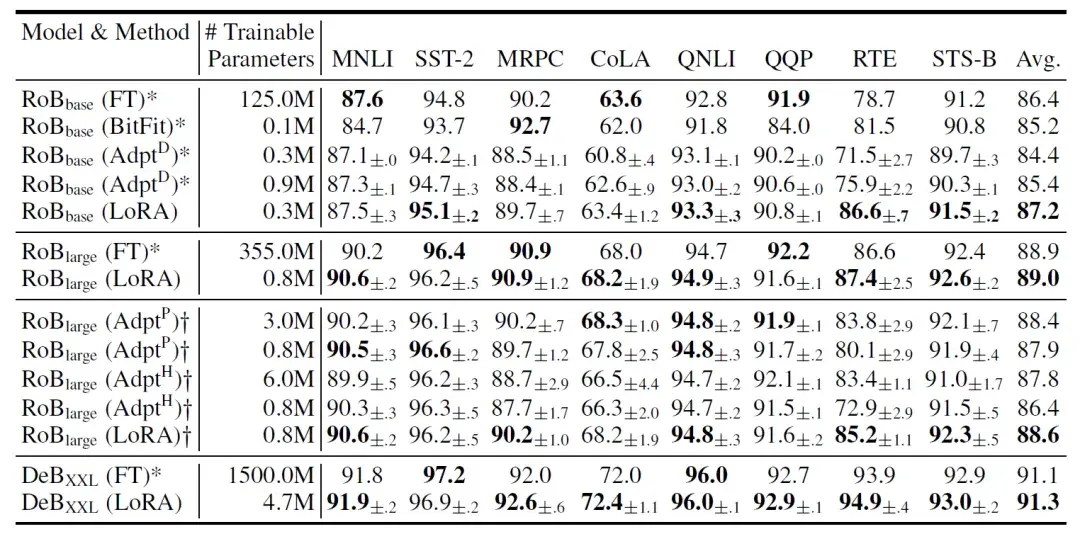
上图左侧为原始论文的配图,右图为另外的视角。举个例子,若原始权重W为d*k的格式,那么一共存在4096(d)×4096(k)=16,777,216个参数。
这时候LoRA使用A(d*r)和B(r*k)来代表权重更新,因为A和B的矩阵相乘也是d*k维度的。假设r为8,则LoRA需要更新的权重参数为4096×8+ 8×4096 =65,536个参数。<一下子要更新的模型参数下降了N倍!>
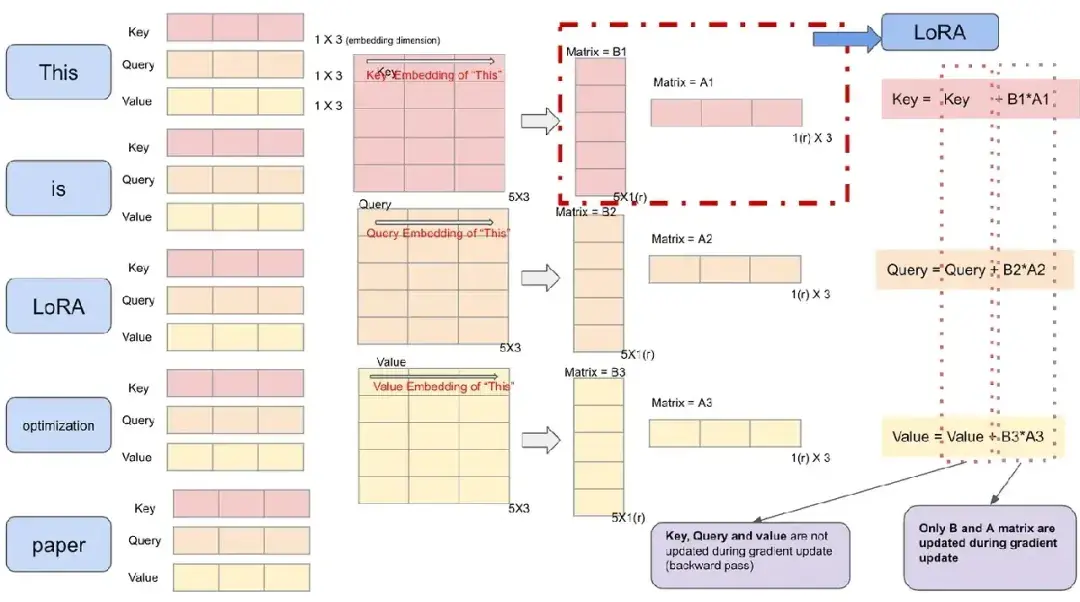
具体的训练过程是这样的,将原来的矩阵参数固定,然后利用新的数据继续训练大模型,而这个训练过程仅仅更新A和B矩阵。在推理使用的时候,将原来的矩阵W和(A*B)相加。下图为可视化版本:
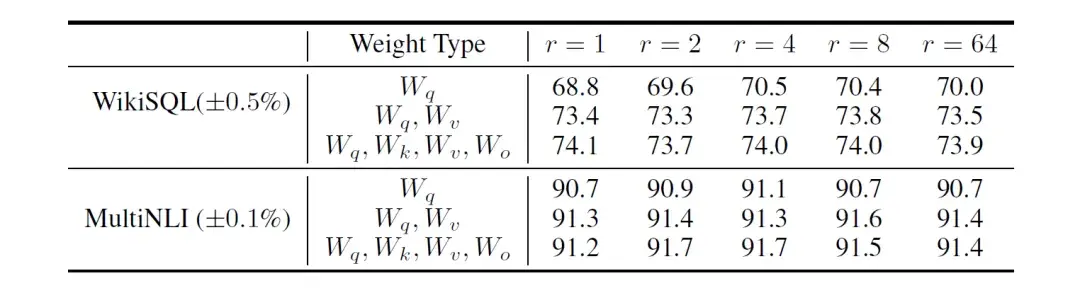
r如何选择,什么的数值是合理的?原始的论文在某些模型上给出了实验的结果,一般而言都是r=4或者r=8,当然这个超参数还是需要具体场景具体分析。
从先期的实验数据而言,LoRA的效果还是不错的。然而LoRA最主要的问题在于矩阵被投影到更小的维度上,因此在此过程中肯定会丢失一些信息。
在各种方法和基础模型中,LoRA在减少训练参数和性能保障之间的确表现优异。
伴随着量化技术,可以将量化引入LoRA,因此诞生了QLoRA。例如神经网络的权重存储为32位浮点数(FP32)。量化可以将其转换为较低精度的点,例如16位或者8位(UINT-8或INT8)。
DoRA
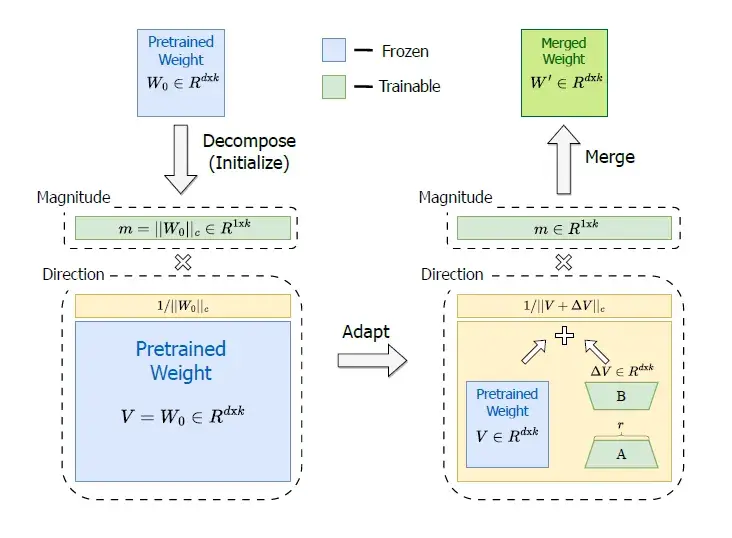
权重分解低秩适应 (DoRA) 将预先训练的权重分解为两个分量:幅度和方向。如下图所示,原来参数矩阵W的维度依旧是d*k,新增了一个幅度向量m(1*k)。
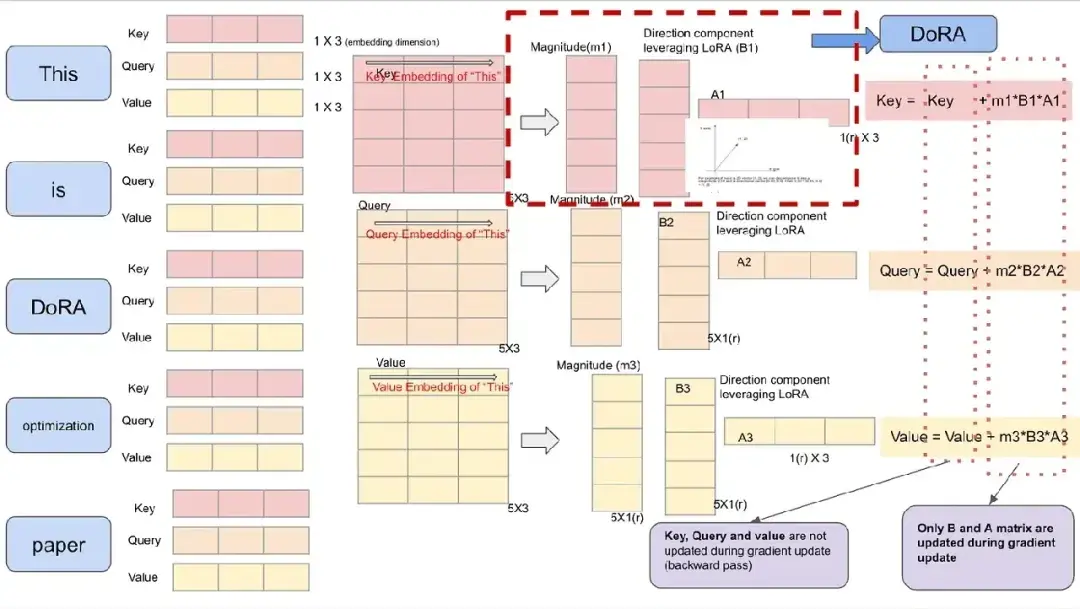
上图绿色部分为需要被训练,而蓝色部分的参数表示在微调训练中是被冻结的。DoRA在训练A和B矩阵的时候,还是利用了LoRA的办法。然而新增了幅度M向量。
可以将矩阵的每列都看成向量,每列的权重矩阵都可以用大小和方向表示。例如可以将[2.0, 3.0]分解为0.5*[4, 6]。在进行完全微调时,梯度更新只是改变了列向量的方向,而幅度却保持几乎恒定。
下图为可视化的过程:
DoRA将列向量分解为2个分量可以更加灵活地更新方向分量,这更接近于完全微调。
MoRA
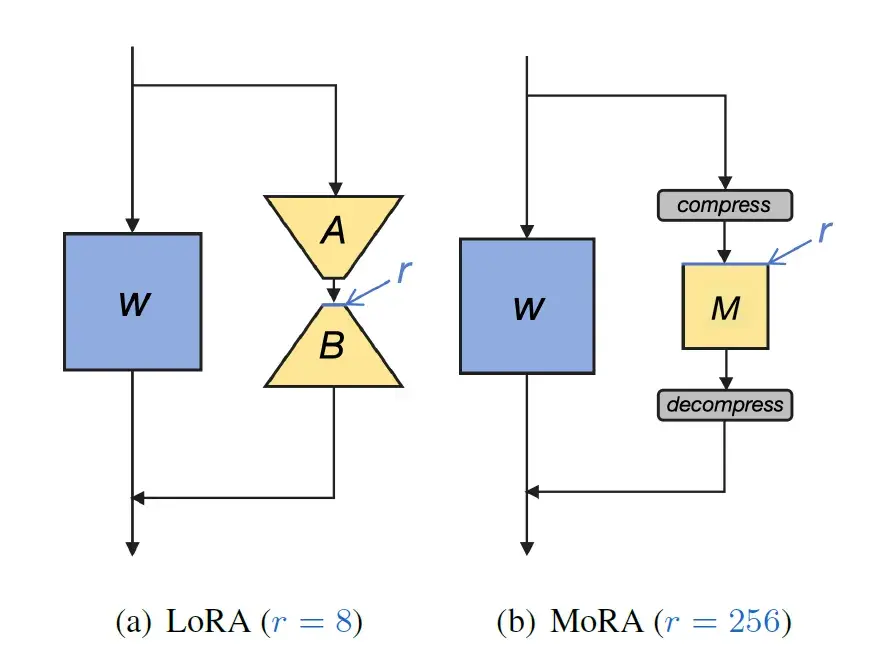
MoRA 的概念类似于 LoRA,但不是将权重矩阵分解为更小的维度,而是将其分解为小的方形矩阵。
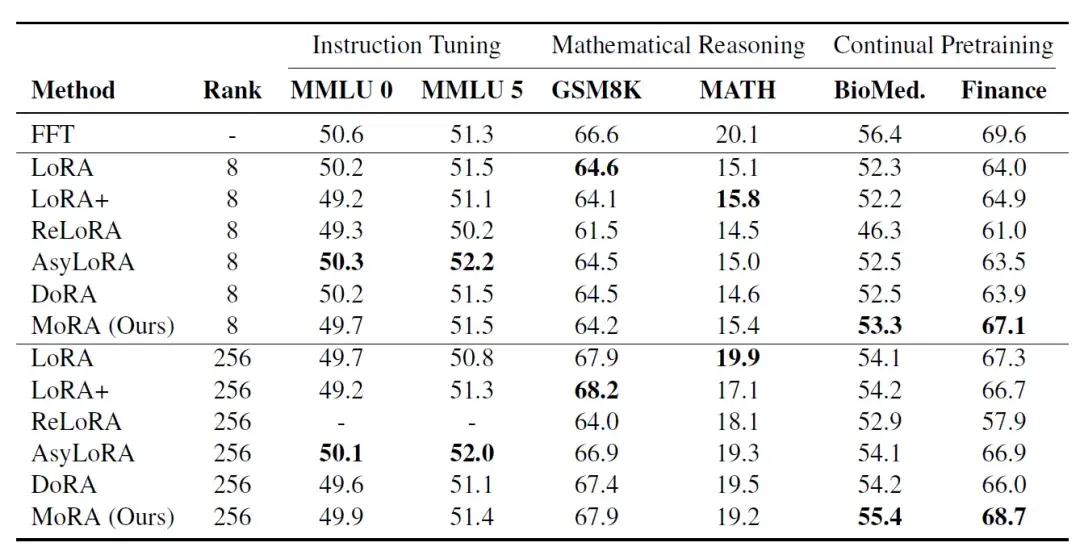
例如,如果原始权重层具有4096×4096~= 16M参数,则r=8的LoRA具有4096×8 + 8×4096=65,536参数。使用MoRA可以将维度减小到r=256,即256×256=65,536。在这两种情况下,需要训练和更新的参数是相同的,然而研究人员声称与LoRA相比具有更高的学习代表性。
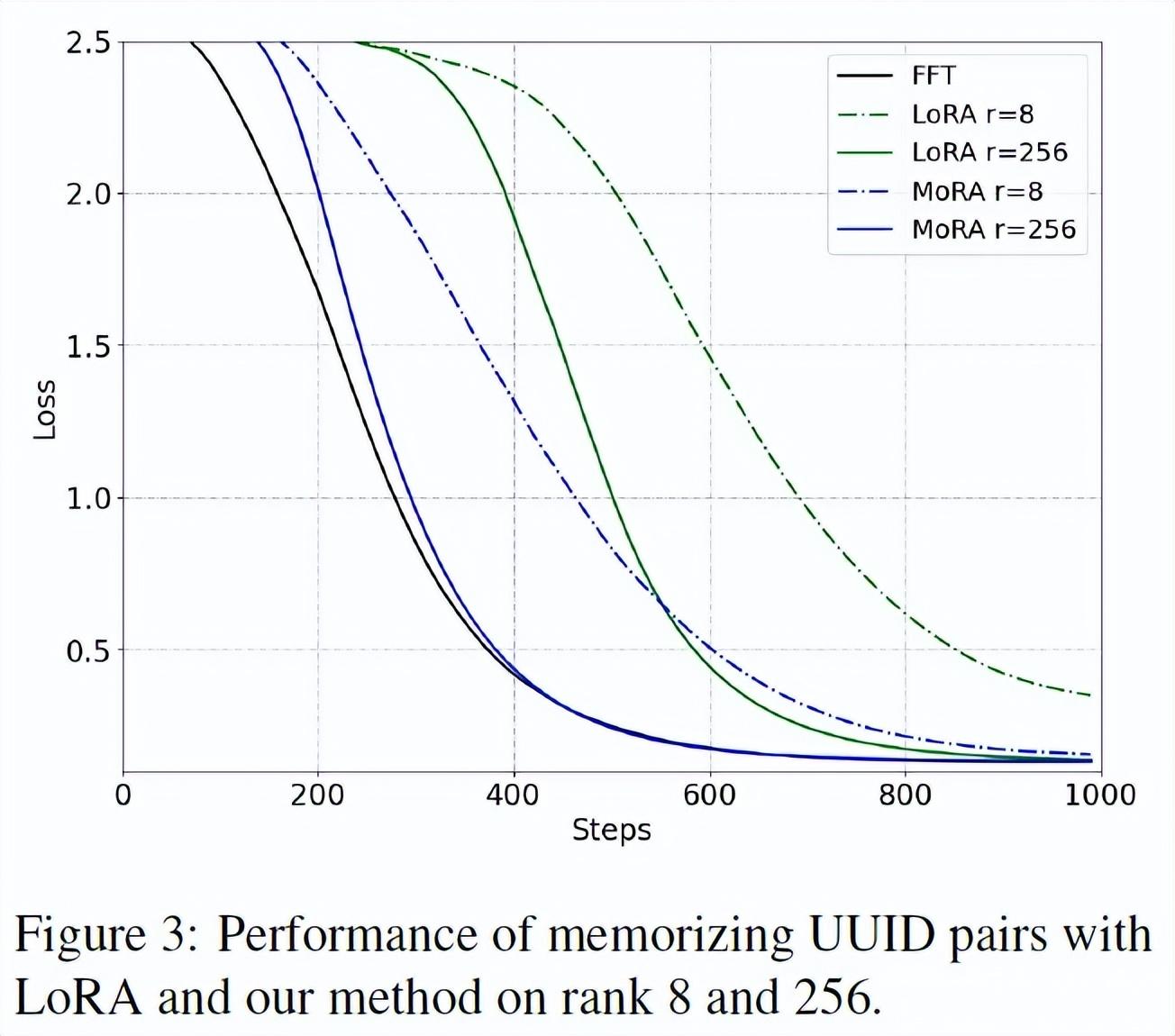
根据这篇2024年5月的论文,LoRA的局限性之一是无法记住大量数据。“对于LoRA观察到的这种限制,一个合理的解释可能是它对低秩更新的依赖。低秩更新矩阵 ∆W ,很难估计FFT中的全秩更新,尤其是在需要记忆特定领域知识的持续预训练等内存密集型任务中。
为了论证这个观点,研究人员研究了LoRA和FFT在通过微调记忆新知识方面的差异。为了避免利用 LLM 的原始知识,研究人员随机生成10K对通用唯一标识符 (UUID),每对包含两个具有32个十六进制值的UUID。该任务要求LLM根据输入的UUID生成相应的UUID。例如,给定一个UUID,比如“205f3777-52b6-4270-9f67-c5125867d358”,模型应该根据10K个训练对生成相应的UUID。这个任务也可以看作是一个问答任务,而完成它所必需的知识完全来自训练数据集,而不是LLM本身。
| 实验的结果辅证了研究人员的说法。MoRA的损失收敛得很快。 |